10. TensorFlow 2.x - CNN 소개
참고: https://youtu.be/1_70qe1XBV8?si=DS8euX9WWLW-NGg1

앞 글에서 Convolution이 무엇인지 대략적인 개념에 대해서 설명했다.
이번에는 이 개념을 이용한 CNN(Convolutional Neural Network)에 대해서 알아보자.
위의 슬라이드는 일반적인 신경망(NN)과 CNN을 비교한 것이다.
겉으로 보기에는 동일한 구조를 가지지만, 내부의 모습이 조금 다르다.
NN에서 은닉층을 convolutio이 들어가도록 구성하고 flatten 층이 있다는 점이 다르다.

CNN에서 각 은닉층(여기서는 컨볼루션층)이 conv, relu, pooling으로 이루어져 있음을 알 수 있다.
conv: 입력 데이터의 특징을 추출하는 역할. 어떻게 특징을 추출하는지는 다음 글에서 보자.
pooling: 입력 데이터의 대표값을 정해서 출력. 다음 연산에서 부하를 줄여주는 역할을 한다.

앞 글에서 소개한 행렬의 convolution을 연산하는 방법이다.
conv 연산 결과와 바이어스(bias)를 더한 값을 특징 맵(feature map)이라 부른다.
필터는 가중치의 집합체, 스트라이드는 필터와 입력데이터를 연산할 때 이동하는 간격을 말한다.

위에서 relu를 설명하지 않았는데, 이것은 NN에서도 사용하는 함수로,
0보다 큰 경우, 입력값이 그대로 출력하고,
0보다 작으면 0을 출력한다.
pooling은 보통 max pooling을 많이 사용하는데 주어진 입력에서 제일 큰 값을 출력한다.

convolution 층을 잘 살펴보면 입력에 비해 출력의 크기가 작은 것을 볼 수 있다.
당연한 이야기이지만, 특징 맵을 만들 때와, pooling을 할 때 모두 필요없는 부분을 모두 잘라내기 때문이다.
패딩은 이와는 반대로 출력의 크기를 어느정도 보존하게끔 하는 역할을 하는데 입력 데이터 주변에 특정 값을 붙여주는 것이다.

그러면, 입력 데이터의 크기, 필터의 크기, 패딩, 그리고 스트라이드(컨볼루션 연산에서 필터가 이동가는 거리)를 가지고 출력 데이터의 크기를 일반식으로 구할 수 있다. (그냥 그렇다고 하고 우리는 결과만 쓰면 될 것이다.)
글을 읽다보면 왜 이런 복잡한 걸 하지? 하는 의문이 들 것이다. 당연히 성능을 높일 수 있기 때문이다.
정말 머리 좋은 분들이 연구해서 결론을 내 놓았기 때문에 이에 대한 의심은 내려놓고 이제 예제를 가지고 사용해 보자. 앞 글에서 했던 MNIST, fashion MNIST 예제를 CNN 구조로 다시 풀어보면 비교하기도 용이할 것이다.
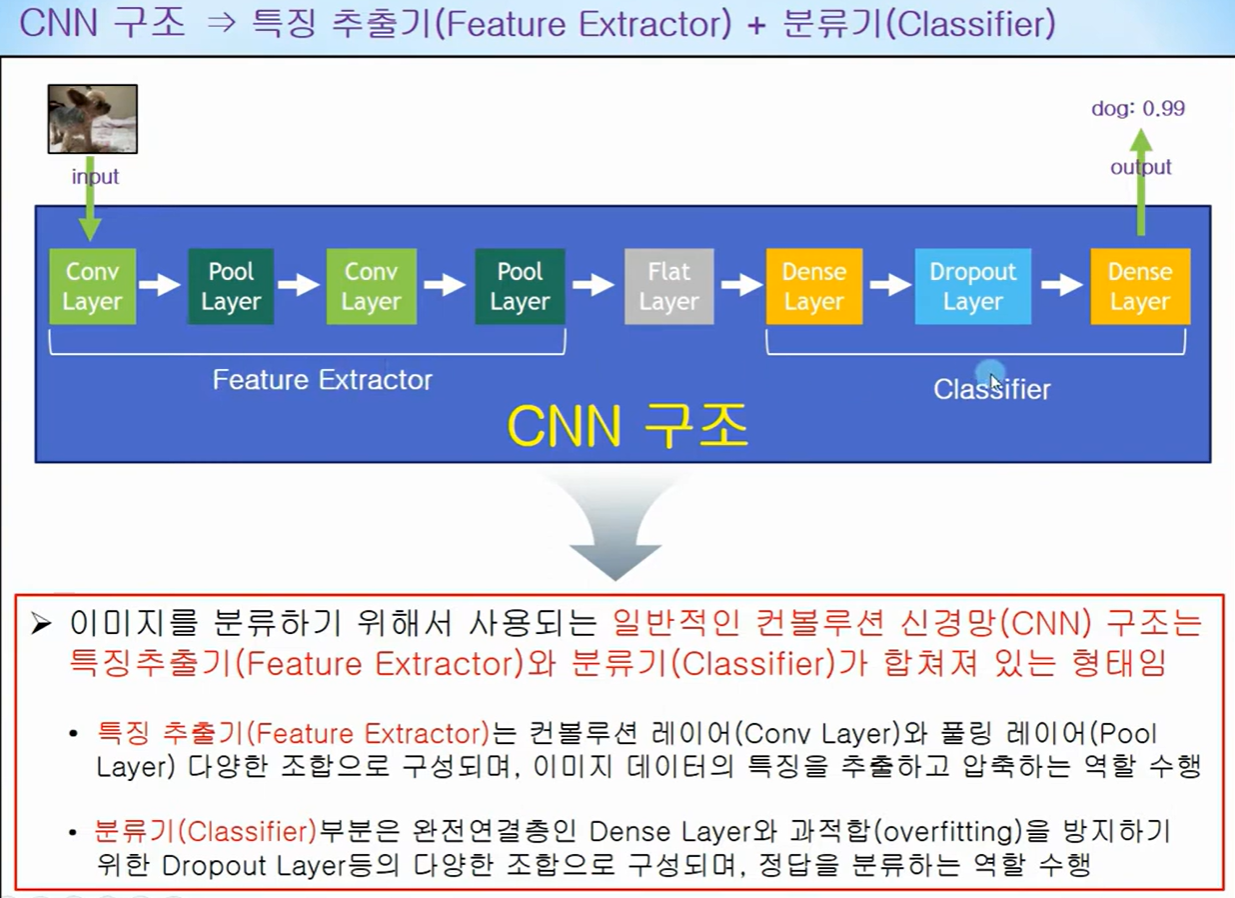
위에서 본 일반적인 CNN 구조를 이미지 구분을 위해서 사용하면 위 슬라이드와 같이 구분할 수 있을 것이다.
특징 맵(feature map)을 만들기 위한 은닉층을 여기서는 특징 추출기라고 부르고 있고,
이 특징들을 가지고 분류하는 은닉층을 분류기라 할 수 있을 것이다.
이제 구조를 알았으니 실제 코드로 만들어보자.


MNIST 데이터를 가지고 와서 CNN 구조에 맞게 변환하고 정규화하는 과정이다.
NN과의 차이점은 입력 데이터의 형식을 변환하는 것이다. (60000, 28, 28) --> (60000, 28, 28, 1)
이제 모델을 만들어 보자.

첫번째 Conv는 28 x 28 x 1 로 변환된 이미지를 입력으로 하고 필터의 크기는 3 x 3 그리고 그런 필터가 32개로,
다음 Conv는 앞의 출력을 그대로 받고, 필터의 크기는 동일 하지만 필터가 64개로 설계한다.
Pooling은 2 x 2 MAX로 사용하고 overfitting을 방지한다는 dropout을 25%로 설정한다.
여기까지가 특징 추출기 부분이다.
컨볼루션층 다음에 은닉층을 넣는데 128개의 노드를 가지도록 설계하고 dropout을 50%로 하며
10가지의 종류로 분류되기에 노드가 10개이고 활성화 함수를 softmax로 하는 출력층을 설계한다.

모델이 완성되었으니, 학습시키고 학습의 결과가 어떤지 살펴보자.
처음 학습할 때는 정확도가 85%, 손실이 0.49였다.

마지막 학습할 때는 정확도가 99.7%, 손실이 0.0097이였다. 엄청난 개선이긴하다.
evaluate으로 평가한 결과는 99.1%의 정확도 손실은 0.0413. 100개 중에 1개보다 적게 틀린다는 이야기니...
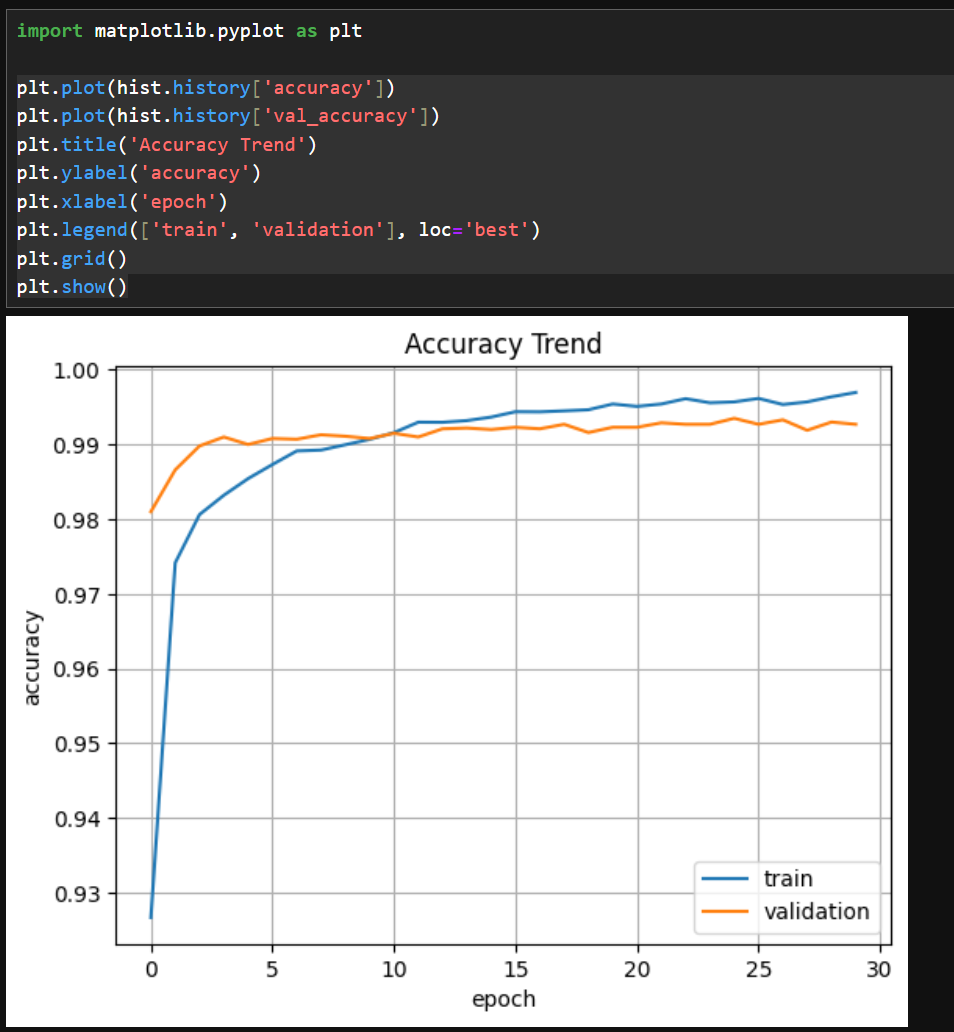
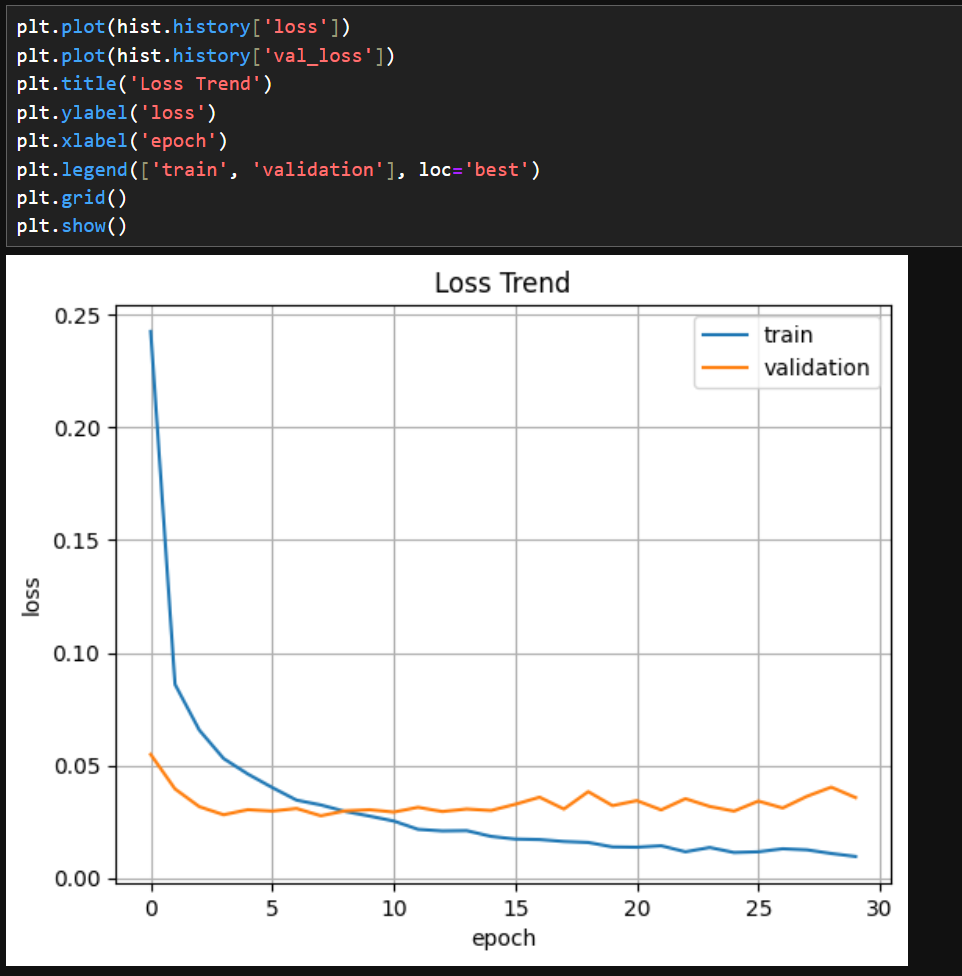
위 그림에 따르면, 정확성은 99% 이상, 손실은 5% 이하이다.
dropout의 효과인지는 모르겠으나, overfitting은 많이 개선된 것으로 보인다.
이번에는 좀더 복잡한 fashion-MNIST 예제를 같은 모델로 다뤄보자.


모델은 같은 것을 사용하기로 하고 데이터들만 받아오고 이것으로 이 모델을 학습시킨다.
처음에는 정확도가 45% 정도로 좋지 않지만, 학습이 완료되었을 때는 95.4%가 되었다.
테스트 데이터로 평가했을 때도 92.5% 이다.


학습용 데이터와 검증용 데이터에 대한 정확도, 손실 값을 보여준다.
약간의 overfitting이 있으나 dropout으로 인해 심하지는 않다.
다음 글에서는 흑백이 아닌 컬러 이미지에 대해서 적용해보도록 하자.