참고: https://youtu.be/zZm0vSBswlM?si=oEc6TqPxCDdbUUmF

지난 글에서 다룬 MNIST예제는 손글씨로 쓴 0부터 9까지의 이미지를 입력하고 그 숫자를 판독하는 것이었다.
이와 비슷하게 Fashion MNIST예제는 위의 슬라이드처럼 옷이나 구두같은 패션에 관련된 이미지를 입력하여, 그 이미지가 무엇인지 판독하게 하는 문제이다. 손글씨와 마찬가지로 학습데이터는 28x28 크기의 이미지들이 60000개가 있고 테스트 데이터는 같은 크기로 10000개가 있어서 제대로 추론 되었는지 모델을 평가해 볼 수 있다.
위 슬라이드에서 딥러닝 모델을 만드는 순서에 대해 잘 정리되어 있다. 이대로 만들어보자.
위에서 말한 대로 fashion MNIST를 다운 받아서 그 크기와 개수를 확인해 보았다.
다운 받은 이미지를 출력해보면 아래와 같다.

코드에서 설명한 대로, 원핫 인코딩을 하지 않고 진행해 보자.
모델을 보면, 28x28 이미지가 입력되므로 1차원 배열로 바꿔주는 Flatten()이 추가되었고,
100개의 노드를 같는 은닉층을 추가, 마지막으로 출력 종류 수와 같은 10개의 노드를 출력층에 추가하였다.

원핫 인코딩을 하지 않는 경우, loss function을 'sparse_categorical_crossentropy'로 설정해줌으로 해결할 수 있다.
이제 학습을 시키고 그 모델을 평가해 보자.
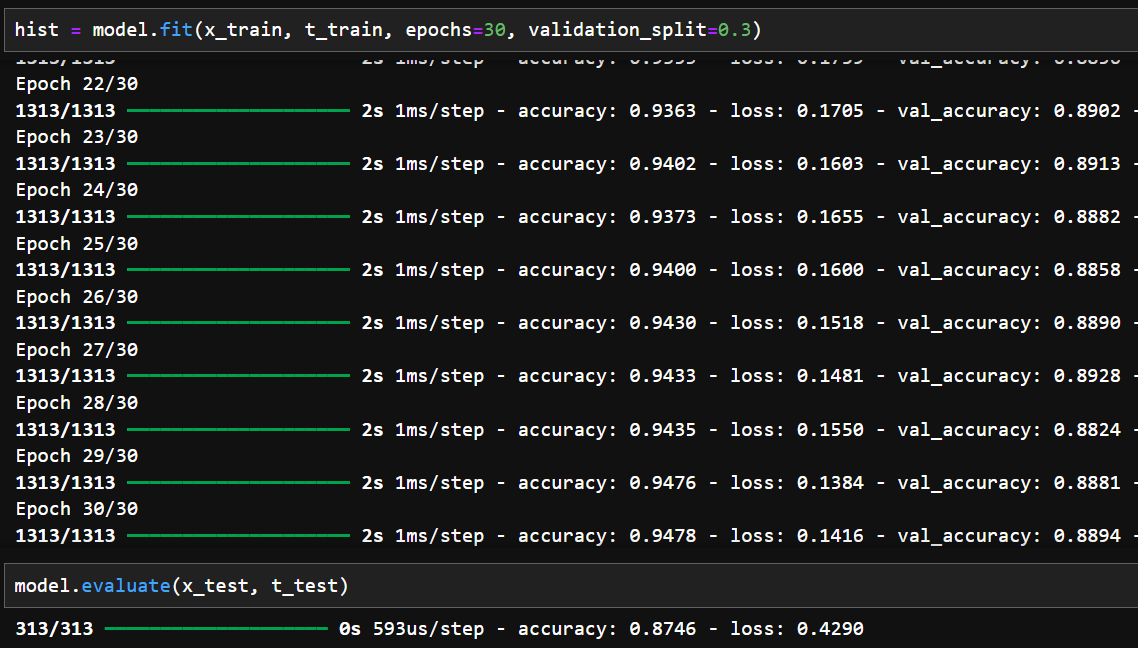
30번 학습한 뒤의 결과를 보면, validation data에 대해 정확도가 89% 정도이고,
테스트 데이터인 경우에 정확도 87%가 된다. 이미지를 판독하는데 30번 학습하고 이정도면 양호한 것으로 보인다.
이제 테스트 데이터와 validation 데이터로 학습하면서 학습 횟수에 따른 loss가 어떻게 변화되는지 보자.

학습할 때 loss는 꾸준히 하락하는데 validation에서는 loss가 어느 이하로 떨어지지 않고 심지어 올라간다.
이 의미에 대해서는 나중에 다시 다루겠다.
이번에 accuracy에 대해서 보자.

정확도도 비슷한 경향성이 보인다. 학습시에는 정확도가 계속 올라가지만,
validation에서는 어느 이상 올라가지 못하고 있다. 학습 도중에 overfitting이 발생했다는 것을 의미한다.
이런 것을 어떻게 해석할지에 대해서는 나중에 다시 다루기로 한다.
이제 혼동행렬을 사용하여 이 모델의 강점과 약점이 어디있는지 살펴보자.
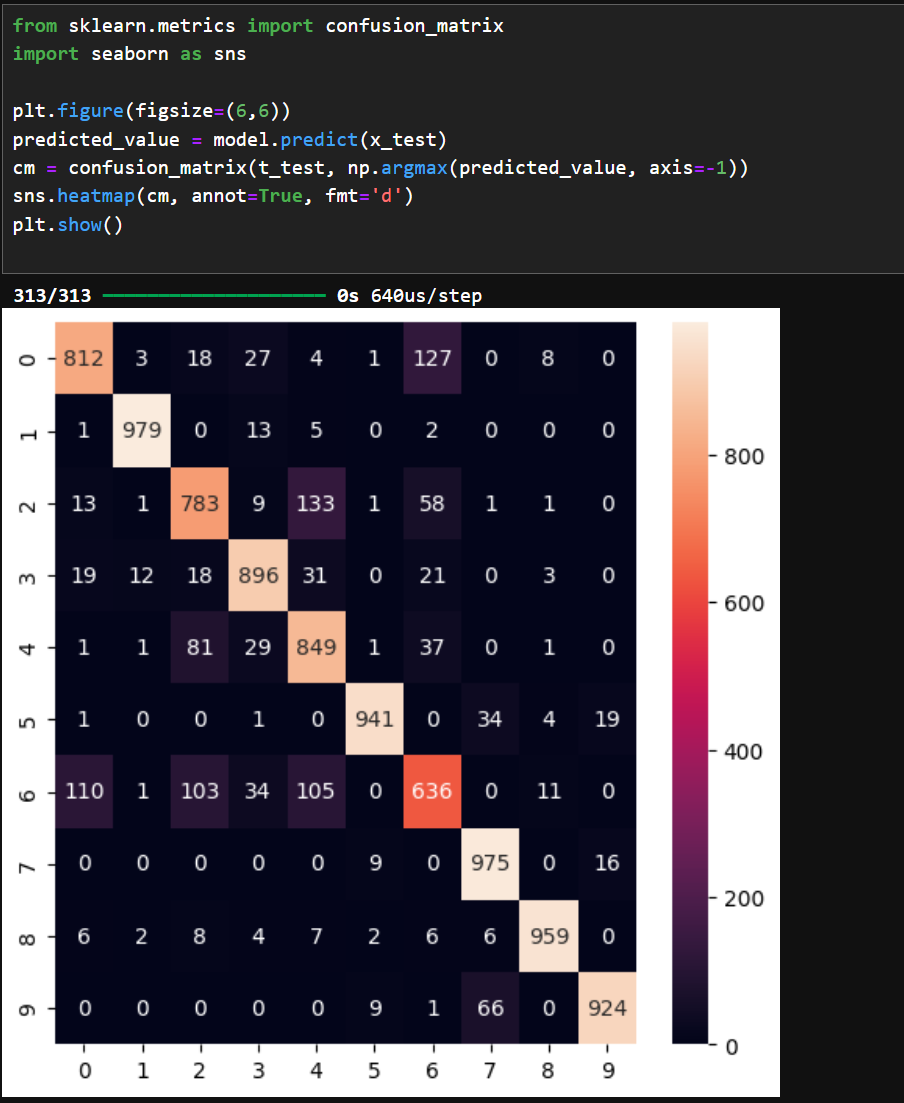
테스트 입력에 대해서 추론한 결과의 분포도를 보면 6번, 2번, 0번에 대한 추론이 약함을 알 수 있다.
테스트 데이터는 총 10000개로 각 종류가 1000개씩있어서 나타난 숫자 자체가 정확도가 된다.
즉, 6번에 대한 정확도는 63.6%, 1번에 대한 정확도는 97.9% 인 것이다.
다음 글에서는 CNN에 대한 내용을 배우기로 한다.
'AI > TensorFlow 학습' 카테고리의 다른 글
| 10. TensorFlow 2.x - CNN 소개 (0) | 2024.08.05 |
|---|---|
| 9. TensorFlow 2.x - Convolution 소개 (0) | 2024.08.02 |
| 7. TensorFlow 2.x - Neural Network MNIST 예제 (0) | 2024.07.31 |
| 6. TensorFlow 2.x - Deep Learning 소개 (0) | 2024.07.31 |
| 5. TensorFlow 2.x - Logistic Regression 예제 (0) | 2024.07.30 |



