참고: https://docs.openvino.ai/2024/notebooks/bark-text-to-audio-with-output.html
Text-to-speech generation using Bark and OpenVINO — OpenVINO™ documentation
Text Encoder Text encoder is responsible for embedding initial text prompt into high-level semantic tokens. it uses tokenizer for conversion input text to token ids and predicts semantic text tokens that capture the meaning of the text. There are some diff
docs.openvino.ai
이번 예제는 Bark라는 미리 학습된 모델로 TTS(text to speech)를 구성하는 실습이다.설명하기로는, 단순히 글자만 소리로 바꿔주는 것이 아니라 더욱 인간과 비슷하게 발음하고, 웃음, 탄식, 울음 등도 표현한다고 하니... 조금 무섭기도 하다. 중국어, 불어, 이태리어, 스페인어 등등도 가능하다고 한다.
이제, OpenVINO에서 이 모델을 어떻게 사용하는지 알아보자.필요한 패키지: torch, torchvision, torchaudio, gradiobark git: https://github.com/suno-ai/bark.git
필요한 패키지를 모두 설치했으면, 모델을 다운로드 받아서 OpenVINO IR 모델로 바꿔보자.
text encoder는 문자들을 의미있는 단어들로 변환하는데 사용된다.
여기까지의 실행 결과는 다운 받은 encoder 모델을 두가지로 저장하는데 하나는 kv_cache input이 가 없는 상태로, 또 다른 하나는 있는 상태로 저장한다. 뒤에서 왜 이렇게 하는지 다시 살펴보자.
여기서 autoregressive transformer인 또 다른 encoder 모델이 등장하는데, 위에서 저장한 text encoder model을 입력으로 받고, 다음 단계를 예측하기 위해서 이전 단계의 결과를 이용한다.
위의 text encoder와 비슷하게 IR 모델로 전환해서 저장하는데, 잠깐 언급한 것 처럼 attention block에 대한 처리를 하는 부분을 볼 수 있다.
coarse encoder를 저장한 것 처럼 이번엔 fine encoder를 저장한다. (coarse model size: 1.25G, fine model size: 3.74G)
fine encoder는 coarse encoder를 이용해서 얻은 과거의 코드북들을 기반으로 다음 코드북을 예측한다고 한다.
일단 변환된 IR 모델들이 어떻게 저장되었는지 보자.
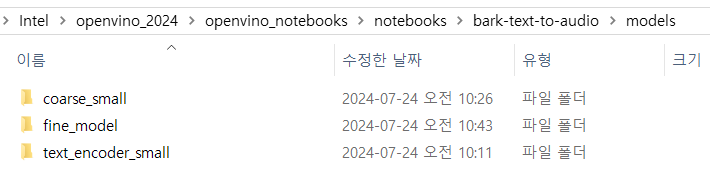

fine model이 6개나 만들어진 것을 볼 수 있다. 무슨 차이가 있는지 뒤에서 살펴볼 것이다.

아래 나오는 generate_audio() 는 입력된 텍스트와 과거의 기록들을 입력으로 받아서 추론 과정을 걸치게 되는데 이 과정은 위의 그림과 같다. Convert Text to Semantic에서 text encoder를 사용하고, Generate coarse codebooks에서 coarse encoder, Generate fine codebooks에서 fine encoder를 거치게 되며 마지막으로 Decode waveform에서 소리로 변환 되는 것이다.
그러면 이를 함수로 구현하는 것은 너무 길어서 맨 아래 코드로 붙여 넣고, 실행해보자.


시간은 꽤 걸린다. 생성된 오디오 파일을 들어보자.

상당히 자연스럽긴 하다. 이것을 실제 10분정도의 script를 주고 변환시키면 시간이 얼마나 걸릴까?
text encoder에서는 첫 단계인지 아닌지에 따라 모델 두개를 바꿔쓰고,
coarse encoder에서는 하나,
fine encoder에서 6개의 fine model을 모두 사용하는 것을 볼 수 있다.
이번엔 지난번 NER에서 사용한 script를 변환하는데 얼마나 걸리는지, 잘 되는지 시험해보자.
"
Rome’s Imperial Period was its last, beginning with the rise of Rome’s first emperor in 31 BC and lasting until the fall of Rome in AD 476. During this period, Rome saw several decades of peace, prosperity, and expansion. By AD 117, the Roman Empire had reached its maximum extant, spanning three continents including Asia Minor, northern Africa, and most of Europe.
"
몇가지 테스트를 해봤는데 이 모델에는 시간 제약이 있는 것 같다.예를 들면 NER에서 사용한 전문을 사용했을 때는 엉뚱한 소리를 하고 있었고, 지금도 목소리가 빠르고, 맨 뒤에 including~ 부터는 나오지 않는다.
아래는 변환하는 코드들을 모아놓은 것이다.
from typing import Optional, Union, Dict
import tqdm
import numpy as np
def generate_audio(
text: str,
history_prompt: Optional[Union[Dict, str]] = None,
text_temp: float = 0.7,
waveform_temp: float = 0.7,
silent: bool = False,
):
"""Generate audio array from input text.
Args:
text: text to be turned into audio
history_prompt: history choice for audio cloning
text_temp: generation temperature (1.0 more diverse, 0.0 more conservative)
waveform_temp: generation temperature (1.0 more diverse, 0.0 more conservative)
silent: disable progress bar
Returns:
numpy audio array at sample frequency 24khz
"""
semantic_tokens = text_to_semantic(
text,
history_prompt=history_prompt,
temp=text_temp,
silent=silent,
)
out = semantic_to_waveform(
semantic_tokens,
history_prompt=history_prompt,
temp=waveform_temp,
silent=silent,
)
return out
from typing import Optional, Union, Dict
def text_to_semantic(
text: str,
history_prompt: Optional[Union[Dict, str]] = None,
temp: float = 0.7,
silent: bool = False,
):
"""Generate semantic array from text.
Args:
text: text to be turned into audio
history_prompt: history choice for audio cloning
temp: generation temperature (1.0 more diverse, 0.0 more conservative)
silent: disable progress bar
Returns:
numpy semantic array to be fed into `semantic_to_waveform`
"""
x_semantic = generate_text_semantic(
text,
history_prompt=history_prompt,
temp=temp,
silent=silent,
)
return x_semantic
from bark.generation import (
_load_history_prompt,
_tokenize,
_normalize_whitespace,
TEXT_PAD_TOKEN,
TEXT_ENCODING_OFFSET,
SEMANTIC_VOCAB_SIZE,
SEMANTIC_PAD_TOKEN,
SEMANTIC_INFER_TOKEN,
COARSE_RATE_HZ,
SEMANTIC_RATE_HZ,
N_COARSE_CODEBOOKS,
COARSE_INFER_TOKEN,
CODEBOOK_SIZE,
N_FINE_CODEBOOKS,
COARSE_SEMANTIC_PAD_TOKEN,
)
import torch.nn.functional as F
from typing import List, Optional, Union, Dict
def generate_text_semantic(
text: str,
history_prompt: List[str] = None,
temp: float = 0.7,
top_k: int = None,
top_p: float = None,
silent: bool = False,
min_eos_p: float = 0.2,
max_gen_duration_s: int = None,
allow_early_stop: bool = True,
):
"""
Generate semantic tokens from text.
Args:
text: text to be turned into audio
history_prompt: history choice for audio cloning
temp: generation temperature (1.0 more diverse, 0.0 more conservative)
top_k: top k number of probabilities for considering during generation
top_p: top probabilities higher than p for considering during generation
silent: disable progress bar
min_eos_p: minimum probability to select end of string token
max_gen_duration_s: maximum duration for generation in seconds
allow_early_stop: allow to stop generation if maximum duration is not reached
Returns:
numpy semantic array to be fed into `semantic_to_waveform`
"""
text = _normalize_whitespace(text)
if history_prompt is not None:
history_prompt = _load_history_prompt(history_prompt)
semantic_history = history_prompt["semantic_prompt"]
else:
semantic_history = None
encoded_text = np.ascontiguousarray(_tokenize(tokenizer, text)) + TEXT_ENCODING_OFFSET
if len(encoded_text) > 256:
p = round((len(encoded_text) - 256) / len(encoded_text) * 100, 1)
logger.warning(f"warning, text too long, lopping of last {p}%")
encoded_text = encoded_text[:256]
encoded_text = np.pad(
encoded_text,
(0, 256 - len(encoded_text)),
constant_values=TEXT_PAD_TOKEN,
mode="constant",
)
if semantic_history is not None:
semantic_history = semantic_history.astype(np.int64)
# lop off if history is too long, pad if needed
semantic_history = semantic_history[-256:]
semantic_history = np.pad(
semantic_history,
(0, 256 - len(semantic_history)),
constant_values=SEMANTIC_PAD_TOKEN,
mode="constant",
)
else:
semantic_history = np.array([SEMANTIC_PAD_TOKEN] * 256)
x = np.hstack([encoded_text, semantic_history, np.array([SEMANTIC_INFER_TOKEN])]).astype(np.int64)[None]
assert x.shape[1] == 256 + 256 + 1
n_tot_steps = 768
# custom tqdm updates since we don't know when eos will occur
pbar = tqdm.tqdm(disable=silent, total=100)
pbar_state = 0
tot_generated_duration_s = 0
kv_cache = None
for n in range(n_tot_steps):
if kv_cache is not None:
x_input = x[:, [-1]]
else:
x_input = x
logits, kv_cache = ov_text_model(ov.Tensor(x_input), kv_cache)
relevant_logits = logits[0, 0, :SEMANTIC_VOCAB_SIZE]
if allow_early_stop:
relevant_logits = np.hstack((relevant_logits, logits[0, 0, [SEMANTIC_PAD_TOKEN]])) # eos
if top_p is not None:
sorted_indices = np.argsort(relevant_logits)[::-1]
sorted_logits = relevant_logits[sorted_indices]
cumulative_probs = np.cumsum(F.softmax(sorted_logits))
sorted_indices_to_remove = cumulative_probs > top_p
sorted_indices_to_remove[1:] = sorted_indices_to_remove[:-1].copy()
sorted_indices_to_remove[0] = False
relevant_logits[sorted_indices[sorted_indices_to_remove]] = -np.inf
relevant_logits = torch.from_numpy(relevant_logits)
if top_k is not None:
relevant_logits = torch.from_numpy(relevant_logits)
v, _ = torch.topk(relevant_logits, min(top_k, relevant_logits.size(-1)))
relevant_logits[relevant_logits < v[-1]] = -float("Inf")
probs = F.softmax(torch.from_numpy(relevant_logits) / temp, dim=-1)
item_next = torch.multinomial(probs, num_samples=1)
if allow_early_stop and (item_next == SEMANTIC_VOCAB_SIZE or (min_eos_p is not None and probs[-1] >= min_eos_p)):
# eos found, so break
pbar.update(100 - pbar_state)
break
x = torch.cat((torch.from_numpy(x), item_next[None]), dim=1).numpy()
tot_generated_duration_s += 1 / SEMANTIC_RATE_HZ
if max_gen_duration_s is not None and tot_generated_duration_s > max_gen_duration_s:
pbar.update(100 - pbar_state)
break
if n == n_tot_steps - 1:
pbar.update(100 - pbar_state)
break
del logits, relevant_logits, probs, item_next
req_pbar_state = np.min([100, int(round(100 * n / n_tot_steps))])
if req_pbar_state > pbar_state:
pbar.update(req_pbar_state - pbar_state)
pbar_state = req_pbar_state
pbar.close()
out = x.squeeze()[256 + 256 + 1 :]
return out
import numpy as np
def semantic_to_waveform(
semantic_tokens: np.ndarray,
history_prompt: Optional[Union[Dict, str]] = None,
temp: float = 0.7,
silent: bool = False,
):
"""Generate audio array from semantic input.
Args:
semantic_tokens: semantic token output from `text_to_semantic`
history_prompt: history choice for audio cloning
temp: generation temperature (1.0 more diverse, 0.0 more conservative)
silent: disable progress bar
Returns:
numpy audio array at sample frequency 24khz
"""
coarse_tokens = generate_coarse(
semantic_tokens,
history_prompt=history_prompt,
temp=temp,
silent=silent,
)
fine_tokens = generate_fine(
coarse_tokens,
history_prompt=history_prompt,
temp=0.5,
)
audio_arr = codec_decode(fine_tokens)
return audio_arr
def generate_coarse(
x_semantic: np.ndarray,
history_prompt: Optional[Union[Dict, str]] = None,
temp: float = 0.7,
top_k: int = None,
top_p: float = None,
silent: bool = False,
max_coarse_history: int = 630, # min 60 (faster), max 630 (more context)
sliding_window_len: int = 60,
):
"""
Generate coarse audio codes from semantic tokens.
Args:
x_semantic: semantic token output from `text_to_semantic`
history_prompt: history prompt, will be prepened to generated if provided
temp: generation temperature (1.0 more diverse, 0.0 more conservative)
top_k: top k number of probabilities for considering during generation
top_p: top probabilities higher than p for considering during generation
silent: disable progress bar
max_coarse_history: threshold for cutting coarse history (minimum 60 for faster generation, maximum 630 for more context)
sliding_window_len: size of sliding window for generation cycle
Returns:
numpy audio array with coarse audio codes
"""
semantic_to_coarse_ratio = COARSE_RATE_HZ / SEMANTIC_RATE_HZ * N_COARSE_CODEBOOKS
max_semantic_history = int(np.floor(max_coarse_history / semantic_to_coarse_ratio))
if history_prompt is not None:
history_prompt = _load_history_prompt(history_prompt)
x_semantic_history = history_prompt["semantic_prompt"]
x_coarse_history = history_prompt["coarse_prompt"]
x_coarse_history = _flatten_codebooks(x_coarse_history) + SEMANTIC_VOCAB_SIZE
# trim histories correctly
n_semantic_hist_provided = np.min(
[
max_semantic_history,
len(x_semantic_history) - len(x_semantic_history) % 2,
int(np.floor(len(x_coarse_history) / semantic_to_coarse_ratio)),
]
)
n_coarse_hist_provided = int(round(n_semantic_hist_provided * semantic_to_coarse_ratio))
x_semantic_history = x_semantic_history[-n_semantic_hist_provided:].astype(np.int32)
x_coarse_history = x_coarse_history[-n_coarse_hist_provided:].astype(np.int32)
x_coarse_history = x_coarse_history[:-2]
else:
x_semantic_history = np.array([], dtype=np.int32)
x_coarse_history = np.array([], dtype=np.int32)
# start loop
n_steps = int(round(np.floor(len(x_semantic) * semantic_to_coarse_ratio / N_COARSE_CODEBOOKS) * N_COARSE_CODEBOOKS))
x_semantic = np.hstack([x_semantic_history, x_semantic]).astype(np.int32)
x_coarse = x_coarse_history.astype(np.int32)
base_semantic_idx = len(x_semantic_history)
x_semantic_in = x_semantic[None]
x_coarse_in = x_coarse[None]
n_window_steps = int(np.ceil(n_steps / sliding_window_len))
n_step = 0
for _ in tqdm.tqdm(range(n_window_steps), total=n_window_steps, disable=silent):
semantic_idx = base_semantic_idx + int(round(n_step / semantic_to_coarse_ratio))
# pad from right side
x_in = x_semantic_in[:, np.max([0, semantic_idx - max_semantic_history]) :]
x_in = x_in[:, :256]
x_in = F.pad(
torch.from_numpy(x_in),
(0, 256 - x_in.shape[-1]),
"constant",
COARSE_SEMANTIC_PAD_TOKEN,
)
x_in = torch.hstack(
[
x_in,
torch.tensor([COARSE_INFER_TOKEN])[None],
torch.from_numpy(x_coarse_in[:, -max_coarse_history:]),
]
).numpy()
kv_cache = None
for _ in range(sliding_window_len):
if n_step >= n_steps:
continue
is_major_step = n_step % N_COARSE_CODEBOOKS == 0
if kv_cache is not None:
x_input = x_in[:, [-1]]
else:
x_input = x_in
logits, kv_cache = ov_coarse_model(x_input, past_kv=kv_cache)
logit_start_idx = SEMANTIC_VOCAB_SIZE + (1 - int(is_major_step)) * CODEBOOK_SIZE
logit_end_idx = SEMANTIC_VOCAB_SIZE + (2 - int(is_major_step)) * CODEBOOK_SIZE
relevant_logits = logits[0, 0, logit_start_idx:logit_end_idx]
if top_p is not None:
sorted_indices = np.argsort(relevant_logits)[::-1]
sorted_logits = relevant_logits[sorted_indices]
cumulative_probs = np.cumsum(F.softmax(sorted_logits))
sorted_indices_to_remove = cumulative_probs > top_p
sorted_indices_to_remove[1:] = sorted_indices_to_remove[:-1].copy()
sorted_indices_to_remove[0] = False
relevant_logits[sorted_indices[sorted_indices_to_remove]] = -np.inf
relevant_logits = torch.from_numpy(relevant_logits)
if top_k is not None:
relevant_logits = torch.from_numpy(relevant_logits)
v, _ = torch.topk(relevant_logits, min(top_k, relevant_logits.size(-1)))
relevant_logits[relevant_logits < v[-1]] = -float("Inf")
probs = F.softmax(torch.from_numpy(relevant_logits) / temp, dim=-1)
item_next = torch.multinomial(probs, num_samples=1)
item_next = item_next
item_next += logit_start_idx
x_coarse_in = torch.cat((torch.from_numpy(x_coarse_in), item_next[None]), dim=1).numpy()
x_in = torch.cat((torch.from_numpy(x_in), item_next[None]), dim=1).numpy()
del logits, relevant_logits, probs, item_next
n_step += 1
del x_in
del x_semantic_in
gen_coarse_arr = x_coarse_in.squeeze()[len(x_coarse_history) :]
del x_coarse_in
gen_coarse_audio_arr = gen_coarse_arr.reshape(-1, N_COARSE_CODEBOOKS).T - SEMANTIC_VOCAB_SIZE
for n in range(1, N_COARSE_CODEBOOKS):
gen_coarse_audio_arr[n, :] -= n * CODEBOOK_SIZE
return gen_coarse_audio_arr
def generate_fine(
x_coarse_gen: np.ndarray,
history_prompt: Optional[Union[Dict, str]] = None,
temp: float = 0.5,
silent: bool = True,
):
"""
Generate full audio codes from coarse audio codes.
Args:
x_coarse_gen: generated coarse codebooks from `generate_coarse`
history_prompt: history prompt, will be prepended to generated
temp: generation temperature (1.0 more diverse, 0.0 more conservative)
silent: disable progress bar
Returns:
numpy audio array with coarse audio codes
"""
if history_prompt is not None:
history_prompt = _load_history_prompt(history_prompt)
x_fine_history = history_prompt["fine_prompt"]
else:
x_fine_history = None
n_coarse = x_coarse_gen.shape[0]
# make input arr
in_arr = np.vstack(
[
x_coarse_gen,
np.zeros((N_FINE_CODEBOOKS - n_coarse, x_coarse_gen.shape[1])) + CODEBOOK_SIZE,
]
).astype(
np.int32
) # padding
# prepend history if available (max 512)
if x_fine_history is not None:
x_fine_history = x_fine_history.astype(np.int32)
in_arr = np.hstack([x_fine_history[:, -512:].astype(np.int32), in_arr])
n_history = x_fine_history[:, -512:].shape[1]
else:
n_history = 0
n_remove_from_end = 0
# need to pad if too short (since non-causal model)
if in_arr.shape[1] < 1024:
n_remove_from_end = 1024 - in_arr.shape[1]
in_arr = np.hstack(
[
in_arr,
np.zeros((N_FINE_CODEBOOKS, n_remove_from_end), dtype=np.int32) + CODEBOOK_SIZE,
]
)
n_loops = np.max([0, int(np.ceil((x_coarse_gen.shape[1] - (1024 - n_history)) / 512))]) + 1
in_arr = in_arr.T
for n in tqdm.tqdm(range(n_loops), disable=silent):
start_idx = np.min([n * 512, in_arr.shape[0] - 1024])
start_fill_idx = np.min([n_history + n * 512, in_arr.shape[0] - 512])
rel_start_fill_idx = start_fill_idx - start_idx
in_buffer = in_arr[start_idx : start_idx + 1024, :][None]
for nn in range(n_coarse, N_FINE_CODEBOOKS):
logits = ov_fine_model(np.array([nn]).astype(np.int64), in_buffer.astype(np.int64))
if temp is None:
relevant_logits = logits[0, rel_start_fill_idx:, :CODEBOOK_SIZE]
codebook_preds = torch.argmax(relevant_logits, -1)
else:
relevant_logits = logits[0, :, :CODEBOOK_SIZE] / temp
probs = F.softmax(torch.from_numpy(relevant_logits), dim=-1)
codebook_preds = torch.hstack([torch.multinomial(probs[nnn], num_samples=1) for nnn in range(rel_start_fill_idx, 1024)])
in_buffer[0, rel_start_fill_idx:, nn] = codebook_preds.numpy()
del logits, codebook_preds
for nn in range(n_coarse, N_FINE_CODEBOOKS):
in_arr[start_fill_idx : start_fill_idx + (1024 - rel_start_fill_idx), nn] = in_buffer[0, rel_start_fill_idx:, nn]
del in_buffer
gen_fine_arr = in_arr.squeeze().T
del in_arr
gen_fine_arr = gen_fine_arr[:, n_history:]
if n_remove_from_end > 0:
gen_fine_arr = gen_fine_arr[:, :-n_remove_from_end]
return gen_fine_arr
'AI > OpenVINO' 카테고리의 다른 글
| 3-12. High-Quality Text-Free One-Shot Voice Conversion with FreeVC and OpenVINO™ (1) | 2024.07.26 |
|---|---|
| 3-10. Named entity recognition(NER) with OpenVINO™ (2) | 2024.07.22 |
| 3-9. Convert a TensorFlow Object Detection Model to OpenVINO™ (0) | 2024.07.19 |
| 3-8. Background removal with RMBG v1.4 and OpenVINO (1) | 2024.07.18 |
| 3-6. Hello Image Segmentation (2) | 2024.07.16 |



