참고: https://docs.openvino.ai/2024/notebooks/hello-segmentation-with-output.html
Hello Image Segmentation — OpenVINO™ documentation
Hello Image Segmentation This Jupyter notebook can be launched on-line, opening an interactive environment in a browser window. You can also make a local installation. Choose one of the following options: A very basic introduction to using segmentation mod
docs.openvino.ai
이번 예제는 주어진 이미지에서 분류(classification)하는 것을 보여준다.
사용할 모델은 road-segmentation-adas-0001이고, 이 모델은 ADAS에서 사용하는 모델로 배경과, 도로, 도로와 인도를 구분하는 연석, 그리고 표식을 분별할 수 있다.
필요한 패키지들을 import하고 모델을 다운받기위해 notebook_utils.py라는 파일을 받아 사용한다.
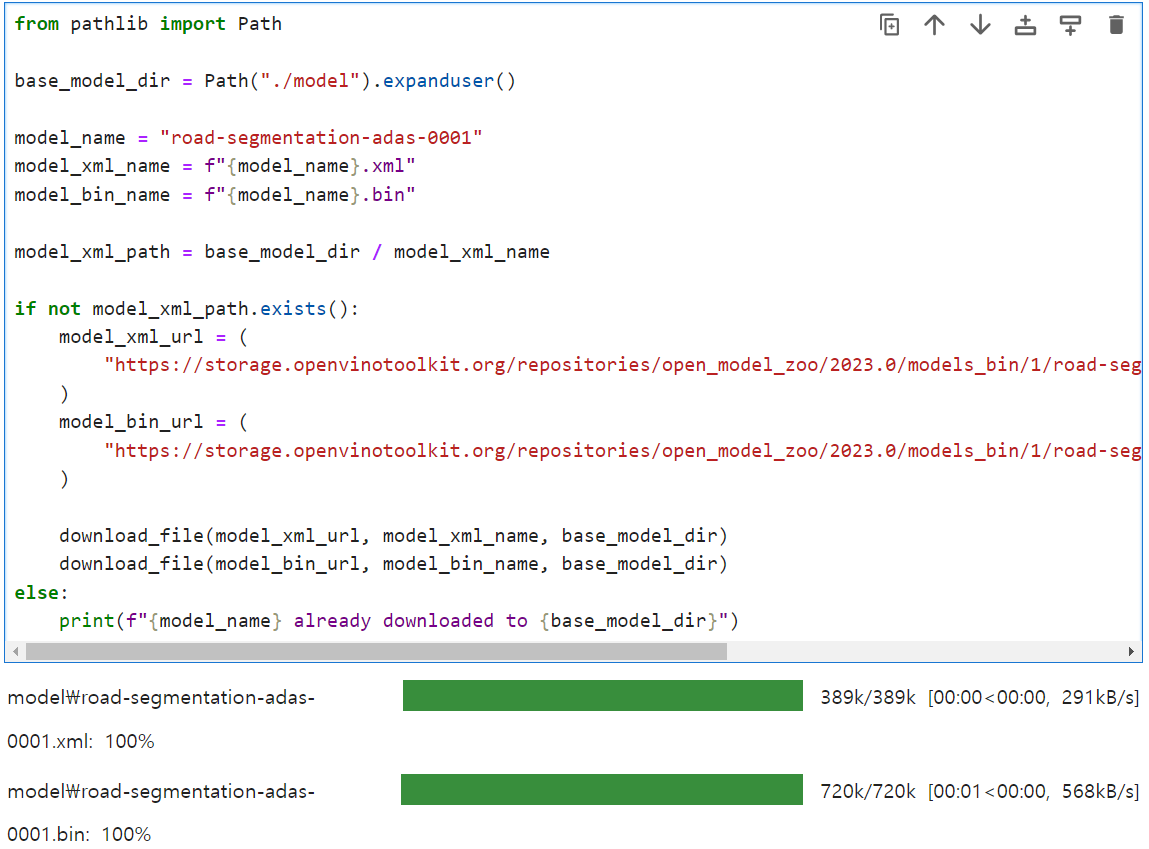
사용할 모델을 다운 받아서 저장한다. 저장위치는 ./model.

모델을 load해주고, input layer와 output layer를 지정. device.value='CPU'


input_layer와 output_layer의 모양을 확인해 놓자.
그러면 입력으로 사용할 이미지를 출력해보고, 모델의 입력 형태로 변형한다.
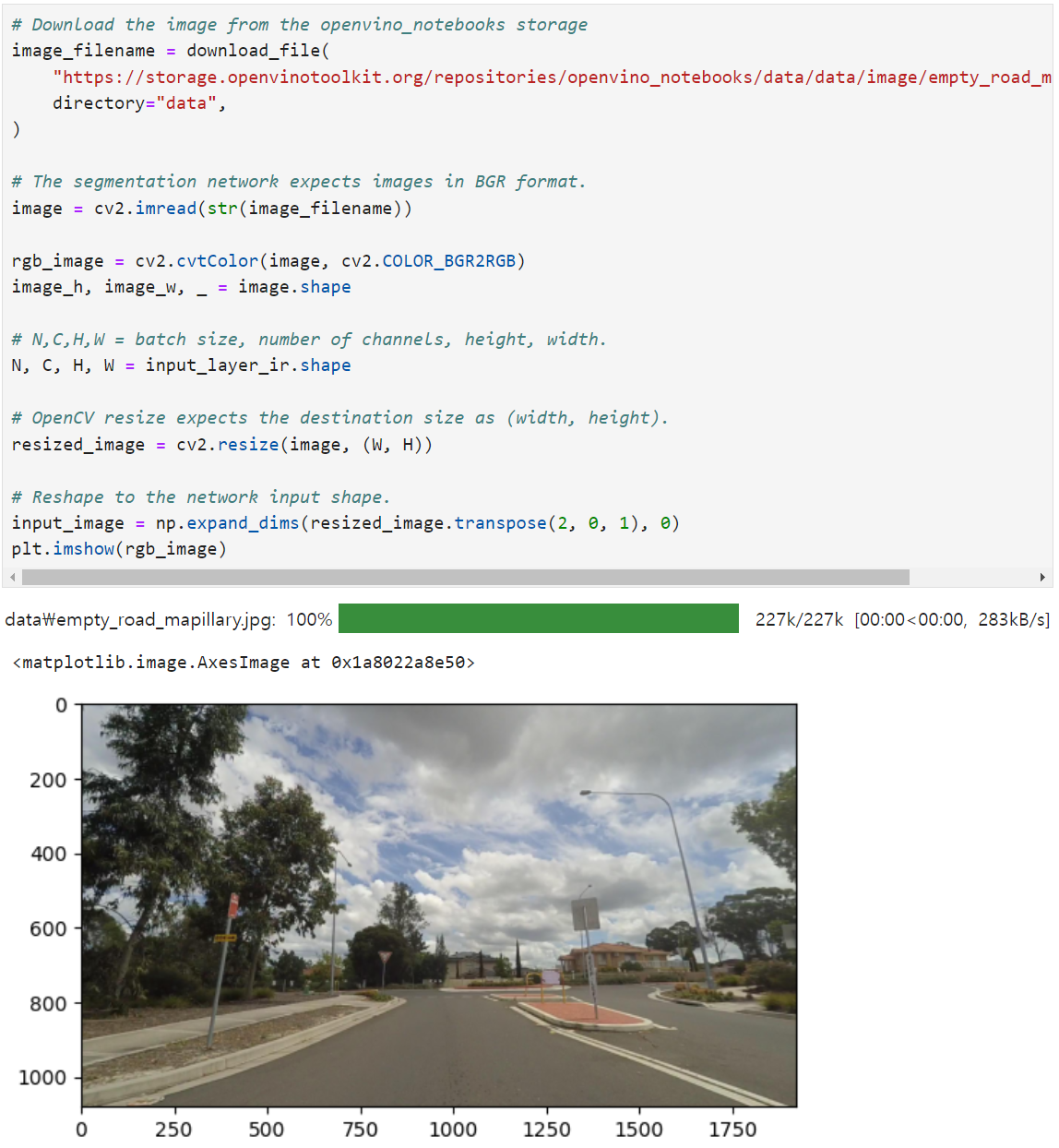
사진의 오른쪽과 아래에 표시된 것 처럼, 그 크기는 1920 x 1080 이기에 이것을 모델 입력의 크기로 만들어주는 과정이 필요하다.(cv2.resize)
이제 입력에 맞춰 변형된 이미지를 넣어주고 어떻게 추론하는지 살펴보자.

위에서 output의 형태를 본 것처럼, (B, C, H, W) = [1, 4, 512, 896]인데
각 C의 의미는 BackGround, road, curb, mark를 나타낸다.
그러면 추론한 이미지를 기존 이미지에 덮어서 표현해 보자.

이 모델이 BG, road, curb, mark(여기서는 차선)을 잘 구분한 것으로 보인다.
그럼 다른 사진도 적용해서 확인해보자.
아래 사진은 어느 인터넷 신문에서 가져온 것이다.
위의 절차대로 이미지를 읽어서 표현해보고, 모델에 넣어서 추론하고, 그 결과를 보자.
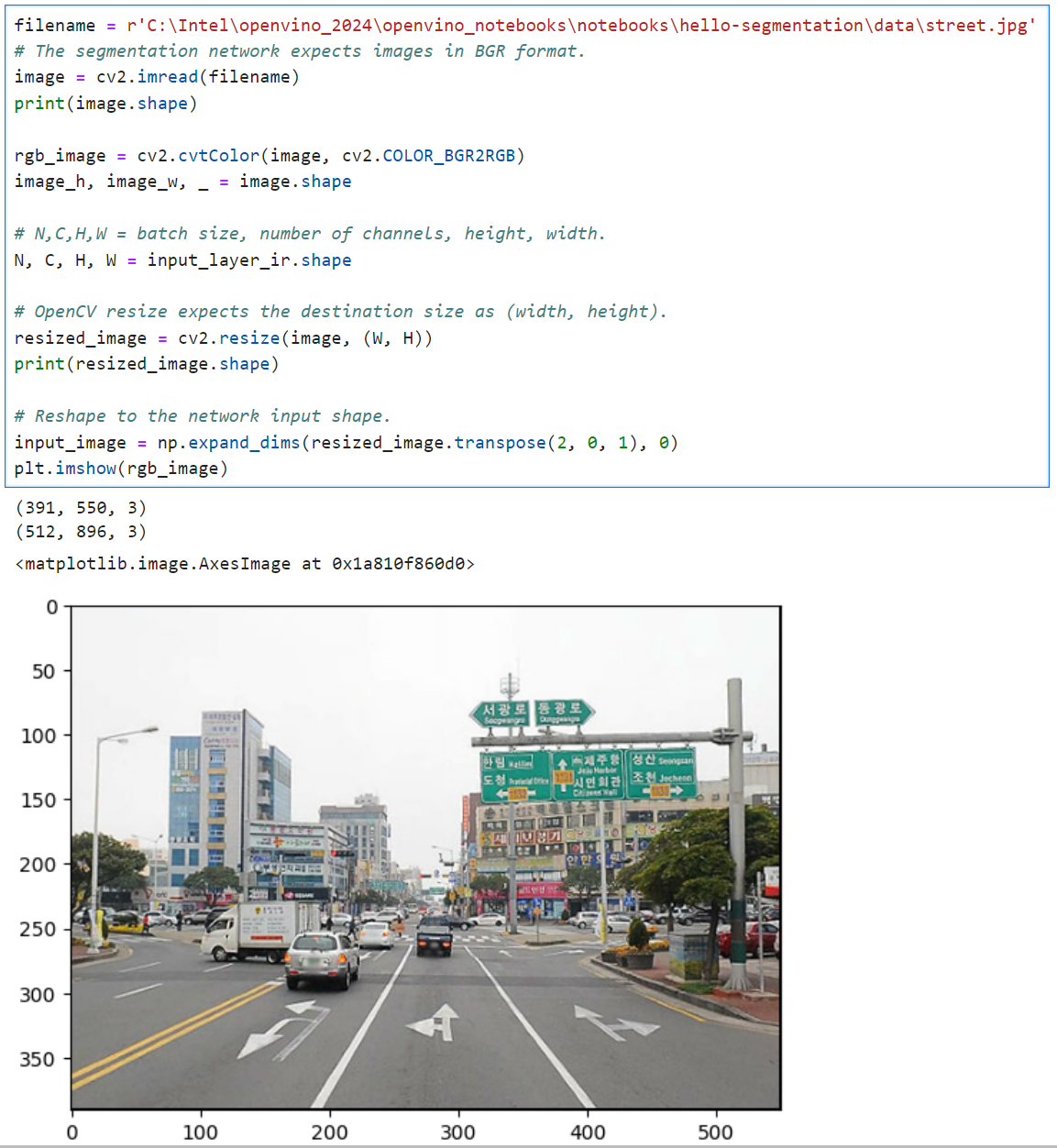

보는 사람에 따라서 잘 된건지... 아닌건지.. 하는 분들도 계실 것이다.
그러면 이것을 원래 이미지와 겹쳐서 보자.

결과물만 크게 보면 아래와 같다.
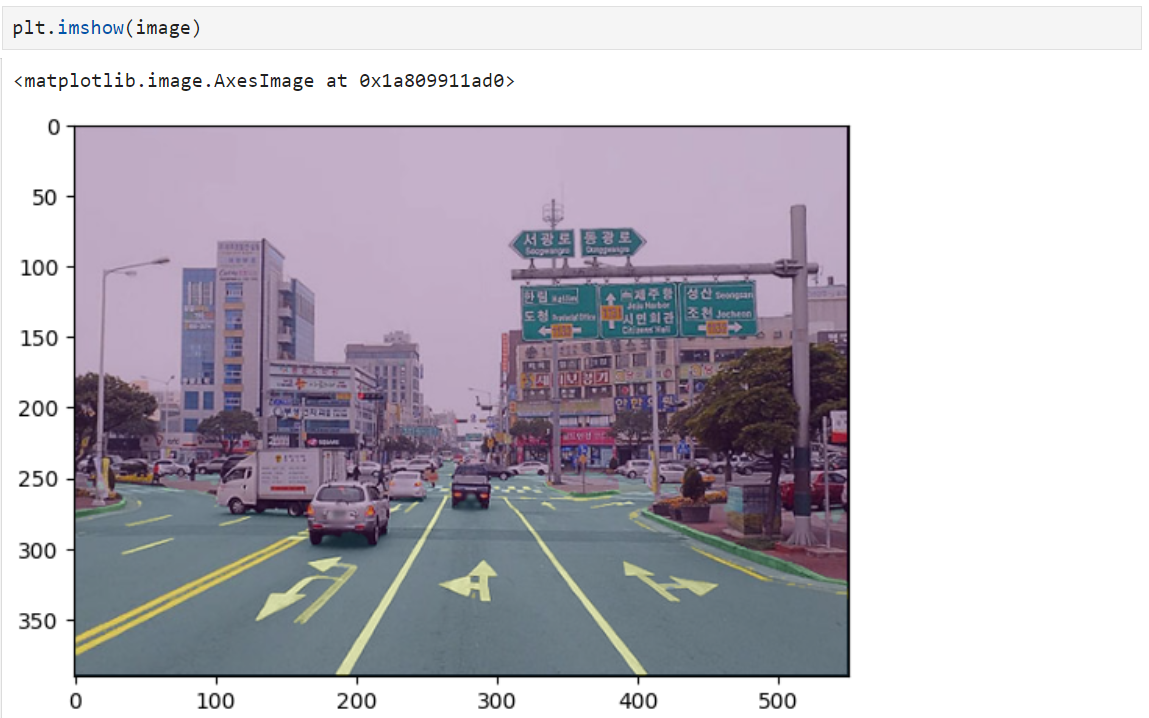
이만하면 성능은 괜찮아 보인다.
'AI > OpenVINO' 카테고리의 다른 글
| 3-9. Convert a TensorFlow Object Detection Model to OpenVINO™ (0) | 2024.07.19 |
|---|---|
| 3-8. Background removal with RMBG v1.4 and OpenVINO (1) | 2024.07.18 |
| 3-5. Hello Image Classification (0) | 2024.07.15 |
| 3-4. Hello Object Detection (2) | 2024.07.12 |
| 3-3. Frame interpolation using FILM and OpenVINO (0) | 2024.07.11 |



